此前,遇到闭包相关的问题,我都会回答,闭包是一种代码环境对另一层代码环境的引用/不释放。但是对于为什么能够实现这样的效果,以及闭包究竟在哪一个环节形成的,闭包什么时候会造成内存泄漏,并不十分清楚。而对于变量对象的概念,网上文章很多,有提及VO/AO的,也有提及词法环境记录器,对象环境记录器等相关内容的,在不说明ECMA版本的前提下容易造成一些阅读上的障碍,再加上变量对象并不能通过代码直观地观测到,我还是不能彻底地理解相关概念。
对于这部分内容,《You Don`t know JavaScript(上)》基于JS代码的编译及执行过程做了阐释,阅读后加上一些网络资料的补充,在这篇文章中梳理阐释作用域/执行上下文/变量对象/this的概念。
特别说明:V8版本更新较快,对于JS实际的执行过程并不完全同文章内容一致,主打概念理解。
编译阶段在掘金很多文章上其实都用预编译阶段进行替代。
编译阶段
JavaScript 是一门编译语言。与传统的编译语言不同的是,JavaScript 不是提前编译的,编译结果也不能在分布式系统中进行移植。
在传统编译语言的流程中,程序中的一段源代码在执行之前会经历三个步骤,统称为 编译。
- 分词 / 词法分析( Tokenizing / Lexing )
- 解析 / 语法分析( Parsing )
- 代码生成
( Content From 《 You Don`t know JavaScript【上】》Page 4 )
编译过程中的关键角色:
- 引擎:从头到尾负责整个 JavaScript 程序的编译及执行过程
- 编译器:负责语法分析及代码生成等步骤
- 作用域:负责收集并维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的
规则,确定当前执行的代码对这些标识符的访问权限
分词 / 词法分析( Tokenizing / Lexing )
阶段说明
这个过程将由字符组成的字符串分解成有意义的代码块,这些代码块被称为 词法单元(token)。
var a = 2; 分解为var,a,=,2,;。
空格是否会被当作词法单元,取决于空格在这门语言中是否具有意义。
分词是基于解析规则将连续的文本划分为独立的词汇单元,而词法分析则是对这些词汇单元进行更深入的分析和理解。
在这个阶段,变量声明的位置已经确定了,大致明确了词法作用域。
用大致主要是V8有预编译和完全编译的区别,不一定在这个阶段把所有代码彻底编译。
词法分析内容(涉及变量/函数提升)
大概分为三步骤,分析参数,分析变量声明,分析函数声明。
- 分析参数:如果存在函数,分析函数的参数分别是什么
- 分析变量声明:分析每一个变量声明,如果是全局变量,进行变量提升
- 分析函数声明:再次分析函数声明,再次进行变量提升
注意这里提及的都只是变量声明,赋值操作应该基于实际情况讨论,有可能在编译阶段,也有可能在执行阶段(个人理解)。
我原本认为,赋值应该只发生在执行阶段,毕竟没有执行代码就算有值也没有使用,但是Page 9提及到
编译器可以在代码生成的同时处理声明和值的定义,比如在引擎执行代码时,并不会有线程专门用来将一个函数值“分配”给某一个函数
考虑到函数声明的变量提升是对声明即整个函数的提升,推测在这个过程中,函数应该完成了赋值。
编译阶段更重要的是分析确定变量位置,为代码的执行提供支持
关于提升⭐⭐⭐
提升是指变量声明或者函数声明会被视为存在于其所出现的作用域的整个范围内。
提升是针对var声明的变量或者函数声明进行提升,函数表达式的提升参考变量的提升而非函数。
函数会首先被提升,函数提升包含实际函数的隐含值,然后才是变量,变量只有声明提升,值没有提升。
重复的var声明会被忽略,但是出现在后面的函数声明可以覆盖前面的!
对于同名变量,后面的赋值,无论是变量赋值还是函数赋值,在赋值代码执行之后都能实现覆盖的效果,要把声明和赋值过程区分开!
( Content From 《 You Don`t know JavaScript【上】》Page 33 40 41 )
区分声明提升和赋值
foo();
var foo;
function foo(){
console.log(1);
}
foo = function(){
console.log(2);
}
引擎理解为
function foo(){
console.log(1);
} // 这里是包括函数声明以及实际函数隐含值都被提升了,所以foo的调用不会报错
// var foo; 同名变量声明,会被忽略
foo(); // 打印1
foo = function(){
console.log(2);
}// 这里是一个函数表达式,不会重复声明,但是在这里执行的赋值操作会覆盖原先foo的内容,所以后续foo打印的是2
// 增加一个foo的调用
foo(); // 打印2
函数表达式不会提升
foo();
var foo = function bar(){
...
}
等价于
var foo;
foo(); // 此处等价于undefined()会抛出TypeError异常
foo = function bar(){
...
var bar = ...self... // 因为是函数表达式,只能在函数自身使用,外层之间调用bar会抛出ReferenceError
}
普通块内函数声明存在的不可控情况
foo(); // TypeError:foo is not a function
var a = true;
if(a){
function foo(){
console.log('a');
}
}else{
function foo(){
console.log('b');
}
}
应该尽可能避免在块内声明函数
aaa(); // TypeError:aaa is not a function
{
function aaa(){
console.log('0')
}
}
❓这到底算bug还是什么…?Page 41
函数声明和函数表达式的区别
- 函数声明
- 以function开头的为函数声明
- 函数声明必须存在函数名称标识符
- 名称标识符绑定在所在作用域中
- 函数表达式
- 不以function开头的,如(function(){})或者var a = function foo(){}等
- 可以没有函数名称,但是最好有,方便代码调试
- 标识符绑定在自身函数中
分词和词法分析的区别
《 You Don`t know JavaScript【上】》中提到分词和词法分析的区别在于词法单元(token)的识别是通过有状态/无状态的规则进行的。
搜索补充了一下这一块的内容:
分词(Tokenizing) 分词是将连续的文本(如句子)划分为一个个独立的词汇单元(或称为“词素”、“词”)的过程。它主要是识别文本中的词汇边界,确定哪些字符序列构成一个独立的词汇单元。这个过程是无状态的,即分词操作只依赖于当前正在处理的字符序列,不依赖于之前的语境或其他状态信息。 词法分析(Lexing) 词法分析是对词汇单元进行更深入的分析和理解的过程。它不仅识别词汇单元,还确定其词性、语法类别等信息。词法分析器通常是有状态的,因为它在分析词汇单元时需要考虑上下文信息或之前的状态。例如,某些语言中的某些词汇可能需要根据上下文或其他词汇的存在来改变其含义或词性。有状态的解析规则使得词法分析器能够处理这种语境依赖性。
目前简单理解为分词就是基于确定规则的切割过程,不会考虑上下文等其他内容
词法分析在分割时会更加深入一些,像上文提到的比如重复的变量声明会被忽略等
解析 / 语法分析( Parsing )
内容
将词法单元流转换成一个 由元素逐级嵌套所组成 的代表了程序语法结构的树。这个树被称为 抽象语法树(Abstract Syntax Tree),AST是babel的基础。
构建AST的过程,作用域和作用域的层次关系(作用域链)已经确定了。
需要注意的是,作用域是一套查找规则,在编译阶段是一个概念上的东西,执行阶段的话能够在变量对象的Scope属性里进行大致分析,即使有闭包的存在,在编译阶段,编译器能够解析出哪些变量会被闭包引用,从而构建作用域链的基本结构。
demo
将var a = 2;转换为AST
{
"type": "VariableDeclaration",
"start": 179,
"end": 189,
"declarations": [
{
"type": "VariableDeclarator",
"start": 183,
"end": 188,
"id": {
"type": "Identifier",
"start": 183,
"end": 184,
"name": "a"
},
"init": {
"type": "Literal",
"start": 187,
"end": 188,
"value": 2,
"raw": "2"
}
}
],
"kind": "var"
}
不同的转换工具会有少许区别。
基于静态作用域的赋值与查找
如果遇到变量的声明,首先会在作用域内查找是否已经存在同名变量,存在则跳过声明。
对于赋值操作,也会在当前作用域先查找是否存在该变量,如果找不到,会基于作用域链往上查找,找到了进行赋值,找不到会报错。
查找的过程需要作用域协助(JS采用词法作用域,变量的值跟书写的位置有关系,需要跟this的值区别开),可以大致分为LHS和RHS查找。
作用域是根据名称查找变量的一套规则,用于确定在何处以及如何查找变量(标识符)
由于这个阶段作用域链大致确定了所以将这部分内容放在了这里。
⏰需要说明的是,编译阶段注重的只是变量的声明位置,作用域嵌套关系,查找赋值一般发生在执行前的预编译阶段。
放在这里主要是也涉及到变量位置的确认,并不表示所提到的赋值和查找均发生在编译阶段。
LHS和RHS
- LHS:找到变量容器本身,以便对其
赋值。非严格模式下如果找不到变量,会去声明它,不会抛出异常,但是严格模式下找不到会抛出ReferenceError异常。 - RHS:
取得某些变量的值,比如用于变量的打印或者函数的调用,找不到会抛出ReferenceError异常。
⏰RHS一般不会发生在编译过程中,编译过程包含变量的声明,在代码没有执行的情况下是不需要去获取变量值或者函数调用的。
赋值声明会被留在原地等待执行阶段
即编译阶段会存在声明a,但是a没有值。
(From 《You Don`t know JavaScript【上】》Page 38)
function foo(a){// 参数a的LRS进行赋值操作(隐式赋值)
console.log(a); // RHS以获取a的值用于console.log
}
foo(2); // 对foo进行RHS
静态词法作用域
const a = 2;
function foo() {
console.log(a); // 如果为静态词法作用域,打印2,动态词法作用域,由于foo是在bar内部调用的,会打印3
}
function bar() {
const a = 3;
foo();
}
bar();
代码生成
将 AST 转换为可执行代码的过程被称为 代码生成。这个过程与语言、目标平台等息息相关。
抛开具体细节,简单来说就是有某种方法可以将 var a = 2; 的 AST 转化为一组 机器指令:创建一个叫做 a 的变量(包括 分配内存 等),并将一个值存储在变量 a 中。
⏰ 这里只是生成指令,还在编译阶段没有执行实际操作。
编译器可以在代码生成的同时处理声明和值的定义,比如在引擎执行代码时,并不会有线程专门用来将一个函数值“分配”给某一个函数
LHS和RHS查询开始于代码的执行阶段,但它们的信息通常在编译阶段就已经准备好了。
JavaScript引擎会在编译阶段进行数项的性能优化,其中有一些优化依赖于能够根据代码的词法进行静态分析,并预先确定所有变量和函数的定义位置,才能在执行过程中快速找到标识符
词法作用域意味着作用域是由书写代码时函数声明的位置来决定的,编译的词法分析阶段基本能够知道全部标识符在哪里以及是如何声明的,从而能够预测在执行过程如何对它们进行查找。
在看到的很多资料里,认为代码执行前编译过程(词法/语法分析/代码生成)为真正的执行过程到来之前的预编译阶段做了准备,帮助预编译阶段变量对象创建,作用域链及this的确定等,还有不少文章直接将编译过程等同于预编译过程。
执行阶段
任何代码都运行在执行上下文中。
执行上下文在代码块执行前创建,作为代码块运行的基本执行环境
执行上下文分类
前面我们提到过,JavaScript中有三种可执行代码块,当然也对应着三种执行上下文。
- 全局执行上下文 — 这是基础上下文,任何不在函数内部的代码都在全局上下文中。它会执行两件事:创建一个全局的 window 对象(浏览器的情况下),并且设置 this 的值等于这个全局对象。一个程序中只会有一个全局执行上下文。
- 函数执行上下文 — 每当一个函数被调用时, 都会为该函数创建一个新的上下文。每个函数都有它自己的执行上下文,不过是在函数被调用时创建的。函数上下文可以有任意多个。每当一个新的执行上下文被创建。
- Eval 执行上下文 — 执行在 eval 内部的代码也会有它属于自己的执行上下文,本文不讨论。
执行栈
一段代码的执行可能涉及到多个执行上下文,通过执行栈进行管理,首先创建全局执行上下文并入栈,如果执行流遇到函数调用,会创建函数执行上下文,压入栈中,每一次函数调用都是新的执行上下文,要区分定义阶段的函数作用域。当函数调用完毕之后,将上下文出栈并销毁,直到代码执行完毕。
执行上下文阶段
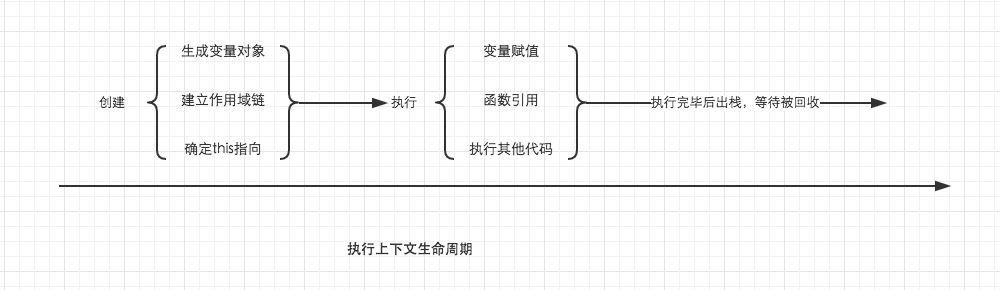
一个执行上下文的生命周期可分为 创建阶段 和 代码执行阶段 两个阶段。
创建阶段:在这个阶段中,执行上下文会分别进行以下操作
- 创建变量对象
- 建立作用域链
- 确定this的指向
变量对象分为ES3版本为VO(对象),AO(函数对象),ES5之后版本为词法环境作用域和声明式作用域,创建作用域链或者创建外部环境的引用,作用域链在打印出来对象的[[Scope]]属性里,Scope里存储的是当前作用域能够访问到的所有外层作用域。概念稍有不同,但是作用类似,重要的是理解这个执行过程。this的指向是在执行时才确定的,下文会提及this的指向问题。
代码执行阶段:创建完成之后,就会开始执行代码,并依次完成以下步骤
- 变量赋值
- 函数引用
- 执行其他代码
对于执行过程更详细的表述,推荐阅读
英文原版 Understanding Execution Context and Execution Stack in Javascript
对于ES6版本的执行过程做了具体的阐述
this指向
说明
this的指向是调用时确定的!变量的作用域是定义时确定的!注意区分!
本质上是个对象,谁调用就指谁,所以使用call/bind/apply时通过this获取调用的对象。
在全局执行上下文中,this 指向全局对象,在浏览器环境下,this引用 Window 对象
在函数执行上下文中,this 的值取决于该函数是如何被调用的。如果它被一个引用对象调用,那么this会被设置成那个对象(apply/bind/call的实现利用了这一点),否则 this的值被设置为全局对象或者undefined(严格模式)。
大概理解为什么要有this指向:
JavaScript中的
this关键字用于指向当前正在执行的函数的上下文对象,它的存在是为了提供对当前上下文的访问权限和操作。这个过程里需要稍微注意构造函数的this指向,箭头函数的this指向,以及可能发生的this指向隐式丢失情况。
想测试自己关于这部分的理解,推荐阅读
【建议👍】再来40道this面试题酸爽继续(1.2w字用手整理)
分类
- 全局对象中的this指向全局,严格模式下是undefined
- 函数的this在函数调用时已经确定,fun(),其中fun是调用者,如果fun被其他对象拥有,比如window.fun(),那么this指向拥有者window(最后一个调用的),否则按第一种情况判断
- 对象的this调用由于{}不会形成单独的作用域所以指的是全局对象(注意:区分作用域【定义时确立】和this指向【执行时且可以被改变】)
- apply/bind/call等用于灵活改变this指向,第一个参数为this的真正指向对象
- new构造函数this指向实例出来的对象
- 箭头函数this指向同外层作用域,且指向函数定义时的this而非执行时(关联知识点:箭头函数跟普通函数的区别)
有两种情况容易发生隐式丢失问题:
- 使用另一个变量来给函数取别名
- 将函数作为参数传递时会被隐式赋值,回调函数丢失this绑定,普通传参及setTimeout均为此种情况
情况一:变量别名导致隐式丢失
function foo () {
console.log(a); // 这里的a表示的是作用域下的a
console.log(this.a); // 这里的a是this对象中的a属性
}
// 注意这里的foo函数不能使用箭头函数,不然直接指向定义时外层的this即window
var obj = { a: 1, foo }
var a = 2;
obj.foo(); // obj调用的foo,this指向obj,打印1
var foo2 = obj.foo;
foo2(); // 隐式丢失,this指向的是window
关于apply/bind/call
- 使用
.call()或者.apply()的函数是会直接执行的,即obj1.fun.call(obj2)等价于obj1.fun(),this为obj2 bind()是创建一个新的函数,需要手动调用才会执行,返回一个bound函数.call()和.apply()用法基本类似,不过call接收若干个参数,而apply接收的是一个数组- 如果
call、apply、bind接收到的第一个参数是空或者null、undefined的话,则会忽略这个参数。 - ⭐
forEach、map、filter函数的第二个参数也是能显式绑定this的
apply
Function.prototype.myApply = function(context, argsArray) {
// 保存原始函数
var fn = this;
var result;
// 如果没有传递上下文对象,则默认为全局对象(非严格模式下)
context = context || window;
// 为上下文对象创建一个唯一的属性,用于保存要调用的函数
var uniqueProp = Symbol('apply');
context[uniqueProp] = fn;
// 执行函数
if (argsArray) {
// 使用展开操作符 `...` 将参数数组传递给函数
result = context[uniqueProp](...argsArray);
} else {
result = context[uniqueProp]();
}
// 删除临时创建的函数属性
delete context[uniqueProp];
return result;
};
bind
// 第一版 修改this指向,合并参数
Function.prototype.bindFn = function bind(thisArg){
if(typeof this !== 'function'){
throw new TypeError(this + 'must be a function');
}
// 存储函数本身
var self = this;
// 去除thisArg的其他参数 转成数组
var args = [].slice.call(arguments, 1);
var bound = function(){
// bind返回的函数 的参数转成数组
var boundArgs = [].slice.call(arguments);
// apply修改this指向,把两个函数的参数合并传给self函数,并执行self函数,返回执行结果
// 内外arguments不同
return self.apply(thisArg, args.concat(boundArgs));
}
return bound;
}
// 测试
var obj = {
name: '若川',
};
function original(a, b){
console.log(this.name);
console.log([a, b]);
}
var bound = original.bindFn(obj, 1);
bound(2); // '若川', [1, 2]
call
call() 方法在使用一个指定的 this 值和若干个指定的参数值的前提下调用某个函数或方法。
- 将函数设为对象的属性
- 执行该函数
- 删除该函数
Function.prototype.myCall = function (context, ...args) {
// 获取调用call的函数
var fn = this;
var result;
// 如果没有传递上下文,则默认为全局对象(非严格模式下)
context = context || window;
// 为上下文对象创建一个唯一的属性,用于保存要调用的函数
var uniqueProp = Symbol('call');
context[uniqueProp] = fn;
// 执行函数
result = context[uniqueProp](...args);
// 删除临时创建的函数属性
delete context[uniqueProp];
return result;
};
闭包⭐
作用域及变量访问规则
在阐述这个概念的时候,我认为还是应该从JS的静态词法作用域开始提起,编译阶段大致确定的作用域和作用域链,确定了变量的访问规则。
作用域分为4种:
- 全局作用域
- 函数作用域
- 块级作用域
- 使用eval/with等创建的作用域(不讨论)
这篇文章里并不想分析不同作用域的区别,让我们聚焦于这套变量访问规则本身。
在JS的规则里,作用域支持嵌套,根据代码的书写位置,内层作用域能够访问外层作用域的变量,而外层作用域不能访问内层作用域的变量(这一点实际上很好理解,一个内层作用域只会有一个直接的外层作用域,但是外层作用域可能包含多个并行的内存作用域,如果内部存在同名变量,即使外层能访问/引用内存,都不好确定要取哪一个,也容易造成不可控的风险)
在嵌套(完全嵌套,不存在某个作用域部分被外层作用域包含的情况)的作用域内,内层作用域和外层作用域如果存在同名变量,在内层作用域对该变量进行访问,存在“作用域遮蔽”效果,即获取/操作只涉及内层作用域的同名变量,不会影响到外层作用域同名变量。
闭包的出现打破了这套规则,在不考虑对象能否形成闭包这一前提下,我们基于闭包形成的常见函数情况对其进行分析。
当函数可以记住并访问所在的词法作用域时,就产生了闭包,即使函数是在当前词法作用域之外执行。
闭包经典例子
function foo(){
var a = 2;
function bar(){
console.log(a)
}
return bar;
}
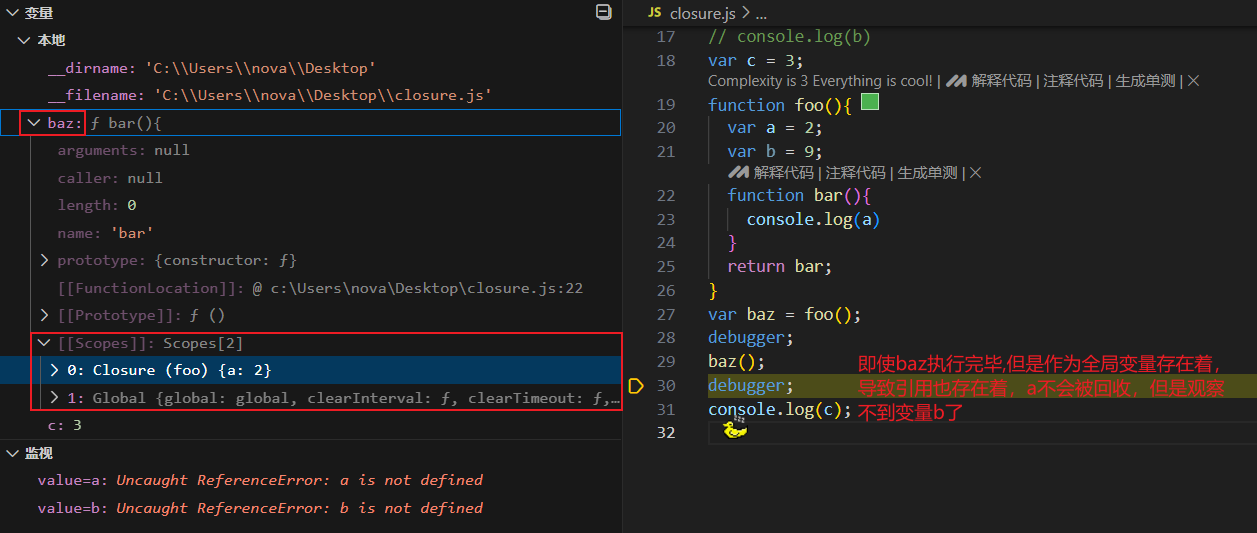
var baz = foo();
baz();
这是一段很典型的使用闭包的代码,对于最外层的全局作用域,存在的变量/函数有foo和baz。
对于foo函数作用域,能够访问到变量a和函数bar,基于此前定义的词法作用域规则,外层作用域即全局作用域中不应该访问到foo作用域中的a或者bar。
由于foo将bar作为返回内容,而bar作用域在foo内部,能够访问a,并且bar将a打印了出来,使得在全局作用域里也使用/观察到了内层作用域的变量。
某种程度上来讲,闭包可以理解为对词法作用域规则的一种突破。
闭包的形成
在这个例子里我们可以得出闭包形成的某种情况:
- 外层函数嵌套内层函数
- 内层函数使用外层函数的局部变量,定义的变量甚至是外层函数参数都行
- 把内层函数作为外层函数的返回值
闭包会产生什么影响?
还是回到这个例子,最直观的影响在于,foo函数调用之后,其作用域环境并不会被回收,因为baz里还存在对foo作用域中a变量的引用,所以在baz函数被销毁或者引用解绑前,foo当时的环境都被保持着,这里注意闭包对环境造成的挟持是整个内部环境的挟持,保持了a的状态。
这里补充一点,我原本以为如果foo函数里存在一个跟a同层的变量var b,b也会因为整个环境内部的挟持而无法回收,实际调试代码发现不是,没有被闭包挟持的变量是能够被正常回收的。
foo的环境在baz函数执行完毕之后也被保存着,这是因为baz是全局环境中的一个变量,后续能够被随时调用,考虑到这种可能性,baz在全局作用域被销毁之前都存在,对foo的引用也存在,所以foo的环境会一直被维持着,如果后续确实对baz有使用要求,这是合理的,否则,应该及时将baz修改为null,以解除这种引用关系,避免内存泄漏。
闭包的使用是否一定会造成内存泄漏?
不一定,解除引用能够避免这种情况。
内存泄漏是指程序中分配的内存未能被释放,导致可用内存减少,最终可能导致性能下降或程序崩溃的情况。在这种情况下,程序仍然占用已分配的内存,但无法再被访问或使用。
上面提到的例子,baz是一直作为全局对象存在所以闭包释放不了,如果baz是存在一个函数内部,那么该函数调用完毕之后,内部环境会被正常销毁。
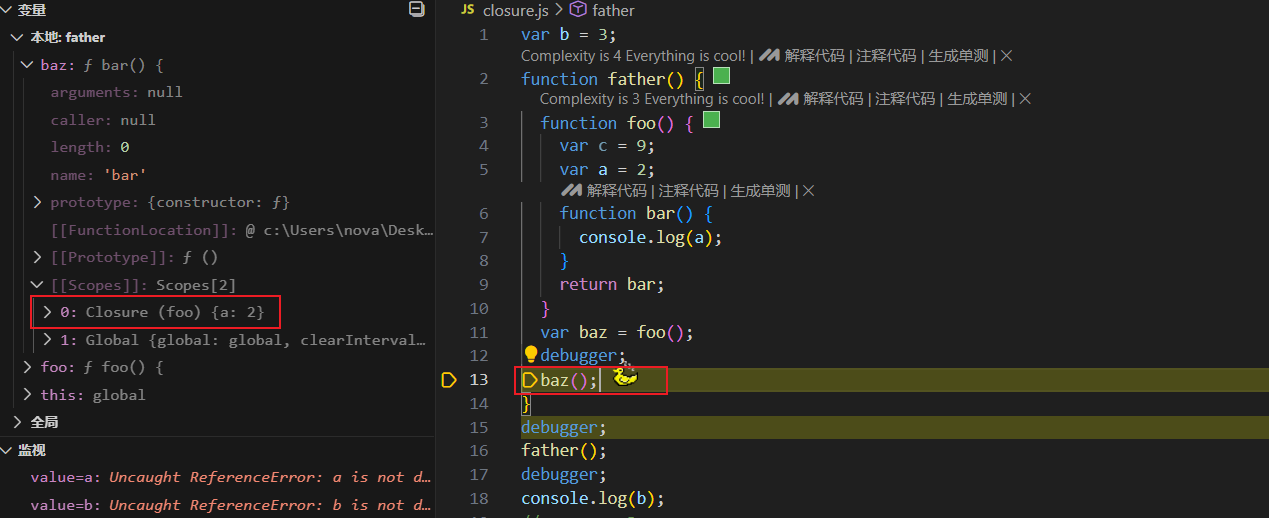
var b = 3;
function father() {
function foo() {
var c = 9;
var a = 2;
function bar() {
console.log(a);
}
return bar;
}
var baz = foo();
// 这里能够明显观察到闭包的存在
baz();
}
father();
// father调用结束之后会被回收,baz也会回收,没有了引用,闭包挟持的内存也会被回收
console.log(b);
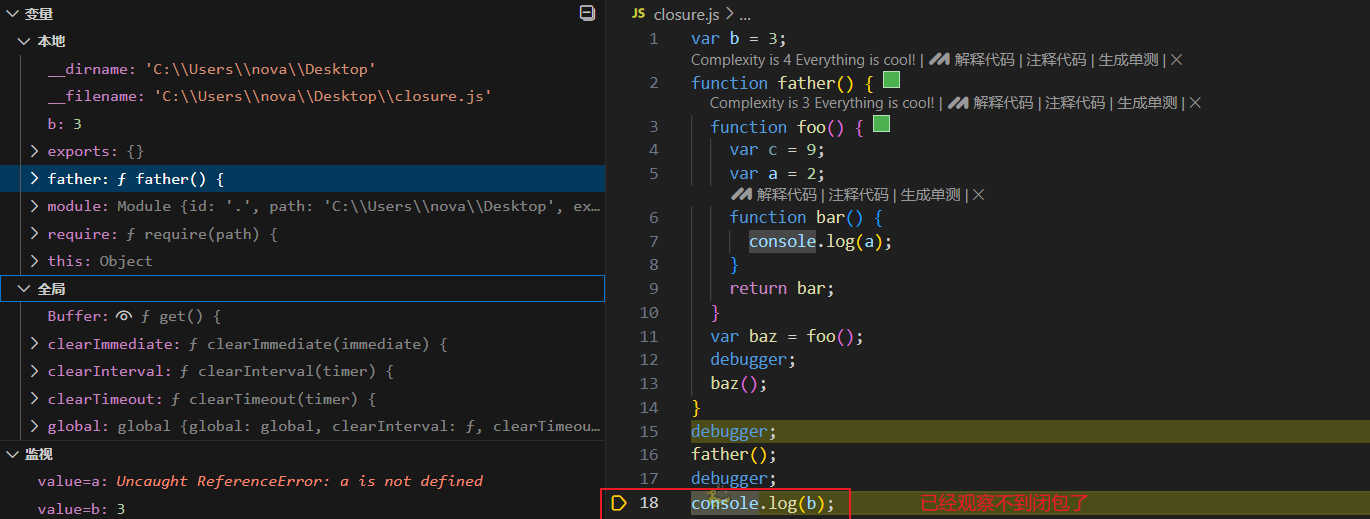
在上一个例子里手动baz=null也能解除引用。
经典问题:对象可以形成闭包吗?
对象本身不能直接形成闭包,但可以通过对象的属性和方法创建闭包。
function createCounter() {
let count = 0; // 外部作用域的变量
return {
increment: function() { // 闭包
count++;
return count;
},
decrement: function() { // 闭包
count--;
return count;
},
getCount: function() { // 闭包
return count;
}
};
}
const counter = createCounter();
console.log(counter.increment()); // 输出: 1
console.log(counter.increment()); // 输出: 2
console.log(counter.decrement()); // 输出: 1
console.log(counter.getCount()); // 输出: 1
这里是间接通过函数产生了闭包,由于对象本身不能形成块作用域,不使用函数的话,严格意义上来讲是实现不了的
但是能够产生类似的效果:跨越词法作用域规则,内存泄漏(个人理解)
function foo() {
var c = 9;
var a = 2;
var b = {d:2,e:{f:{g:2}}};
return { a ,b };
}
var baz = foo();
// 这里实现的效果是外层作用域也访问到了a和b
// 并且baz作用全局变量,不销毁能一直访问a和b
console.log(baz.a);
最大的区别在于这里访问的ab类似拷贝导致的,a其实是实质,b是对象的引用,调试过程并不会将这种情况识别为闭包。
同样的问题:闭包形成一定要return 一个函数吗? 不一定,这里return 一个属性为函数的对象也能形成闭包
闭包的作用
- 通过内层作用域将外层作用域变量暴露出来,这种方式不会创建全局变量,暴露的方式既可以访问局部变量,又能限制对该变量对象的操作
- 如果存在实际需要,能够将需要使用的变量一直保持在内存中
题目
function fun(n,o) {
console.log(o);
return {
fun:function(m){
return fun(m,n);
}
};
}
var a = fun(0); a.fun(1); a.fun(2); a.fun(3);//undefined,?,?,?
var b = fun(0).fun(1).fun(2).fun(3);//undefined,?,?,?
var c = fun(0).fun(1); c.fun(2); c.fun(3);//undefined,?,?,?
解析
a.
function fun(n,o) {
console.log(o);
return {
fun:function(m){
return fun(m,n);
}
};
}
var a = fun(0); a.fun(1); a.fun(2); a.fun(3); // undefined,0,0,0
// var a = fun(0); 很简单就是fun函数执行了一次调用,参数n=0,o=undefined,先打印了一个undefined
// 由于返回的对象中使用了fun中的参数n,所以fun的函数作用域并没有被销毁,n=0,o=undefined都被保持着
// a.fun(1)执行的是函数表达式function(m){...}
// 该表达式应该理解为
// function(m){
// var res = fun(m,n);
// return res;
// }
// 实际上就是执行了fun(m,n),m为1,n从作用域链获取,即n=0;
// 所以打印了0
// 后续只是修改了m的值,n一直都是作用域中的0,所以一直在打印0
// 答案:undefined,0,0,0
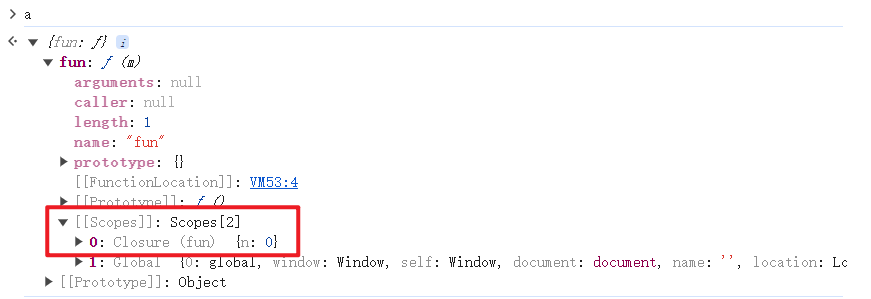
浏览器中可以很明确得看到闭包的存在,a的scope属性中n值为0
b.
function fun(n,o) {
console.log(o);
return {
fun:function(m){
// 仍应该理解为var res = fun(m,n)
// return res;
return fun(m,n);
}
};
}
var b = fun(0).fun(1).fun(2).fun(3);
// fun(0).fun(1)的调用方式跟a最大的区别在于连续的调用是否是针对返回对象里fun属性值里的函数进行的连续调用
// 属性里对fun(1) fun(2) fun(3)函数的调用实质是在调用全局里面的fun(1,0),fun(2,1),fun(3,2)
参考资料
- 《你不知道的JavaScript【上】》
- 【建议👍】再来40道this面试题酸爽继续(1.2w字用手整理)
- JavaScript深入之call和apply的模拟实现
- [译] 理解 JavaScript 中的执行上下文和执行栈
- Understanding Execution Context and Execution Stack in Javascript
- 什么是词法分析?请描述下js词法分析的过程?
- 什么是闭包?闭包的作用是什么?